画像ファイルから簡単に文字起こし
印刷物をスキャンしたデータやスクリーンショットなど、画像ファイルになっているデータから文字を抽出できたら良いのにと思ったこと、ありますよね。
仕方なく画像を見ながらWordで文字を打ち直す……入力ミスが起きる可能性もありますし、とても面倒な作業ですよね。
ところが最近知ったのですが、画像ファイルから簡単に文字を抽出する方法ができたようで、実際に試したら本当に便利だったので紹介したいと思います。
使用するのはGoogleが提供しているストレージサービスの「Googleドライブ」。
まずは文字を抽出したい画像をこちらにアップロードします。
今回はこの「ランガレウェブ」のメインヴィジュアルで使用している画像を使ってみましょう。
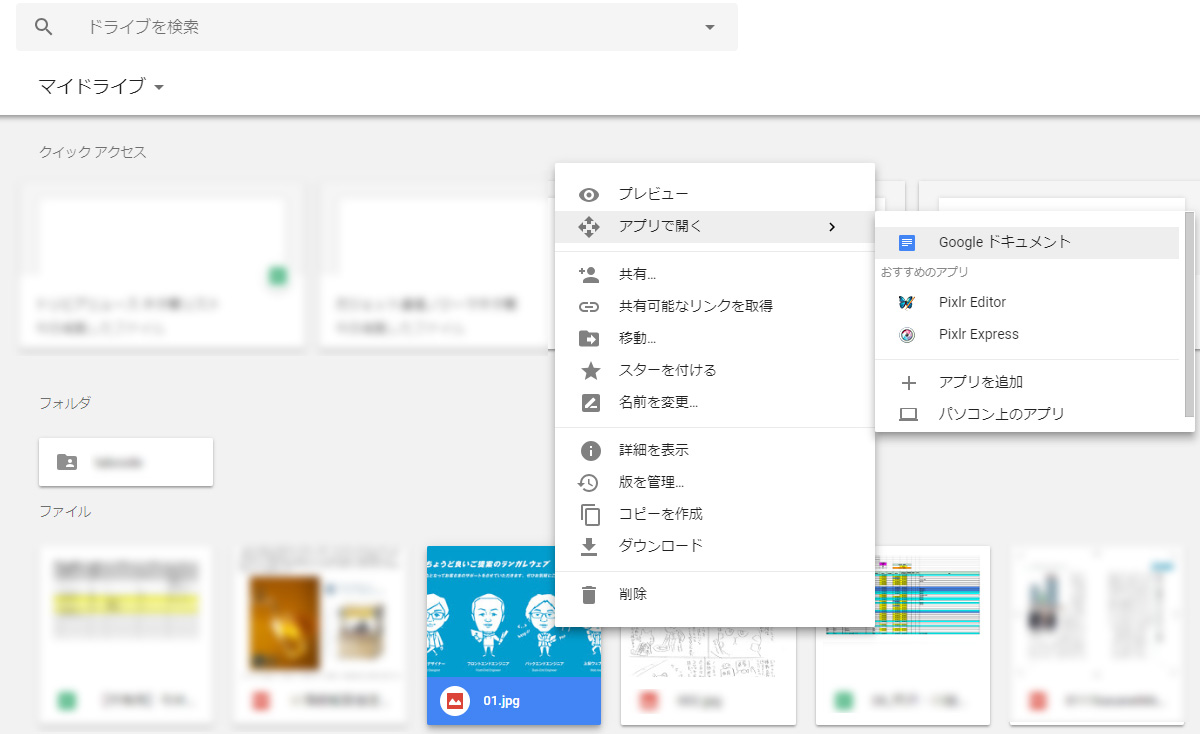
 アップロードしたら、文字を抽出したい画像を右クリックし、「アプリで開く」→「Googleドキュメント」を選択します。
アップロードしたら、文字を抽出したい画像を右クリックし、「アプリで開く」→「Googleドキュメント」を選択します。
 すると、以下のような形で表示されました。
すると、以下のような形で表示されました。
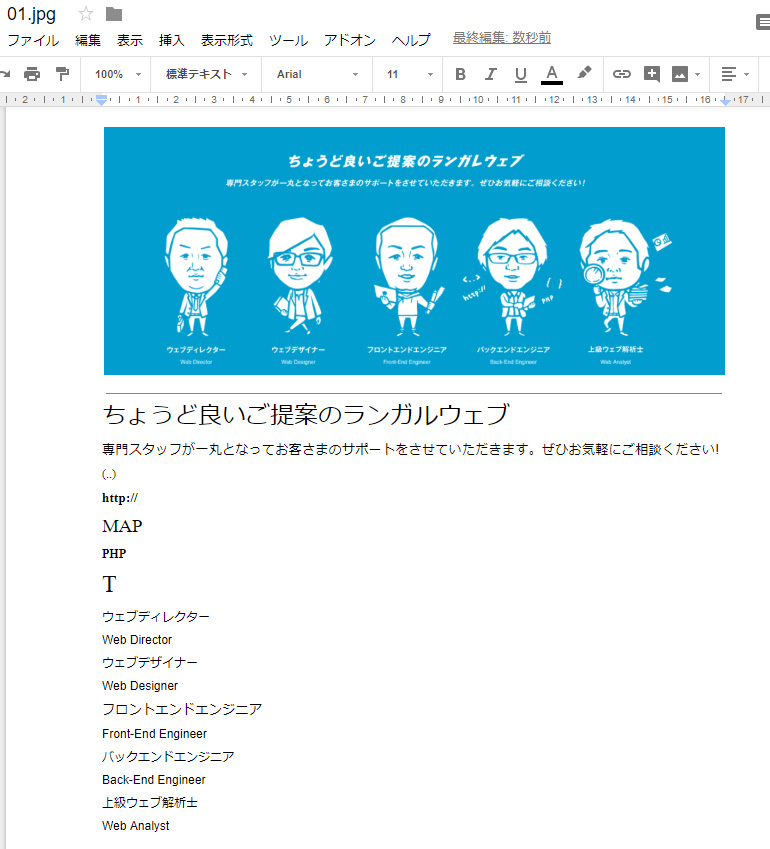 画像ファイルの下にバッチリ文字データが抽出されています。これは便利!
画像ファイルの下にバッチリ文字データが抽出されています。これは便利!
よく見るとロゴをそのまま使用した「ランガレウェブ」の部分が「ランガルウェブ」と抽出されていましたが、その他は完璧でした。
内容はしっかりチェックしたほうが良さそうですが、精度は十分高そうですし、何より文字入力する手間が省けるのは相当な時間短縮に繋がるのではないでしょうか。
Webライター野島
ライター兼Webディレクター。ライティングは真面目な記事からくだけた記事まで、どんなジャンルでも読みやすさを第一に心がけて書いています。 最近はアレンジレシピ関連の仕事もひっそりとこなしているらしい。